I've been reading some philosophy books lately, and the way my mind likes to reason about things always comes back to my software development background. On the matter of the subjective versus objective points of view, my brain immediately thought about how this would be represented in a relational database structure.
Motivation for this post
On the book "Zen and the art of motorcycle maintenance" by Robert M. Pirsig, the main character guides us through his thoughts about the question of "What is quality?". One of the biggest distinctions made in his reasoning is about how we define things through two different points of view: subjective and objective. These two approaches battle each other in every definition we try to make about any concept... "Is there an absolute truth in regards to this?". "Or does this truth depend on who the observer is?". "Can we get to some common agreements?".
I don't want to go in too deep, or even spoil the book to anyone. But I'll just say that even this duality of objective vs subjective is put under scrutiny, and the idea that Quality (this time with capital "Q") precedes this division and so cannot be defined through these lenses is analyzed... If you want more details, go read the book!
Dislaimer
I'm not a philosopher, nor do I have all these abstract concepts completely clear in my mind. It is possible that I'm misusing some of them in the following sections. If that's the case, let me know! =)
A quick word on the objective and subjective points of view

Let's try to understand what the differences are between these two perspectives.
Let's say that:
- we have some entities
- these entities have some properties
- and we ask some observers to tell us what the value of these properties are for these entities
A concrete example might be:
- we have cars
- these cars have properties like "weight" and "practicality"
- we ask some observers to tell us what the value is for the "weight" and "practicality" for each car
For the sake of the example, let's agree on one assumption: "weight" is an objective property and "practicality" is a subjective one. If that is true, then all observers should give us the same value for the weight of the cars, as it is an objective property and can be measured - it is intrinsic to the car itself and it doesn't depend on the appreciation of the observer. But for practicality, we might get different values from each observer. Maybe they appreciate different things when evaluating the practicality of a car. And because it depends on the observer, it is a subjective property.
So, objective properties are intrinsic to the entity and don't depend on the observer. On the other hand, subjective properties arise from the appreciation of the observer when interacting with the observee (yes, that's a word!).
A quick word on relational databases
NOTE: This is by no means a complete overview of relational databases theory. I just want to go over the basics and necessary concepts to lay the groundwork for the "objective vs subjective" example implementation.
Tables
Relational databases are used to organize data into tables, and relate these tables via defined relationships. Each table is used to represent an entity that we want to store in the database, and has a set of columns that represent the properties of the entity. Tables are much the same as what maybe we are used to do in spreadsheets. Each row in the table represents an instance of the entity being stored on the table, with the values of its properties or attributes defined for each column.
An important thing about relational databases, is that each table needs to have a special column: the identifier column (or primary key). The value in this column needs to be unique across all records of the table, and its used to identify each entity unambiguously.
Note: it may be that the primary key is a combination of multiple columns, but for simplicity we will not get into those complications (if you are interested, see composite keys.
Following our example in the previous sections, we could represent observers in its table:
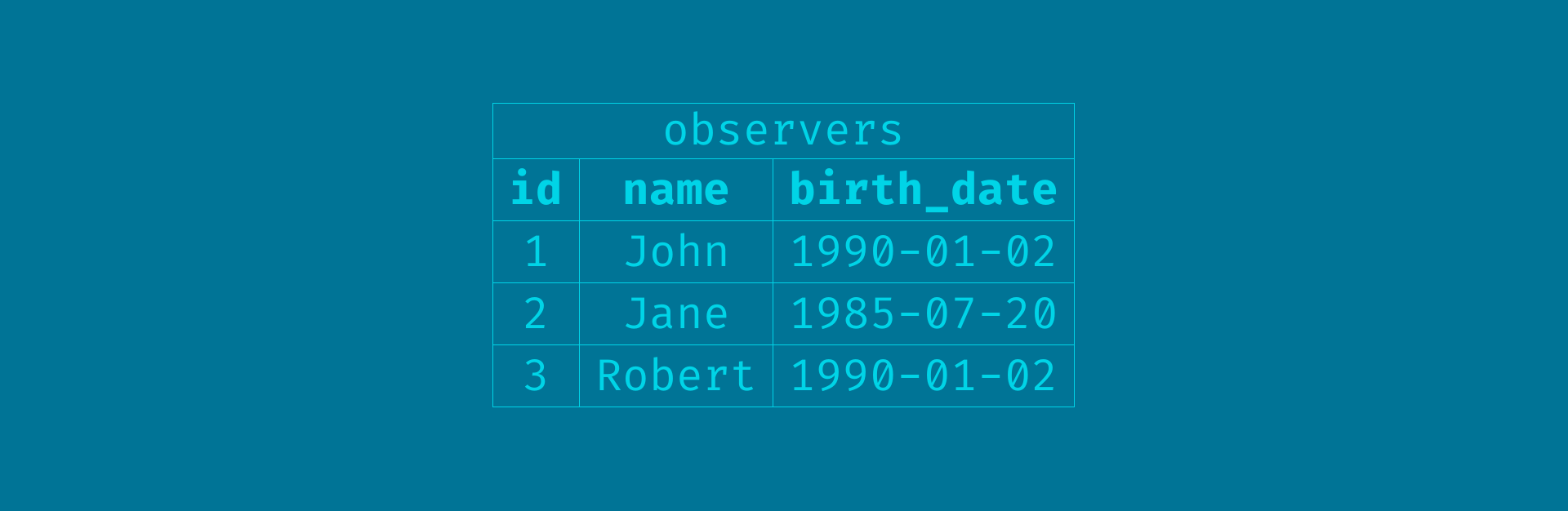
base observers table
Here we defined three obervers of our experiment. Each observer has the attributes: id, name and birth_date. The id column is the primary key of our table: it must be unique.
Relationships
Now, tables are only one part of the equation. We need a way to connect entities between tables. This is where "relationships" come in to play. The primary keys of each table become really important again, as they are used as reference values.
The way these relationships impact the tables' structure depends on the cardinality of the relationship:
One to One
When each record of one table is related to only one record of another, and viceversa. These tables could be merged into one, but for different reasons (like clarity, or security) they can be separated.
Let's say we wanted to store the contact information of every observer.
We could add the relevant columns on our observer table:
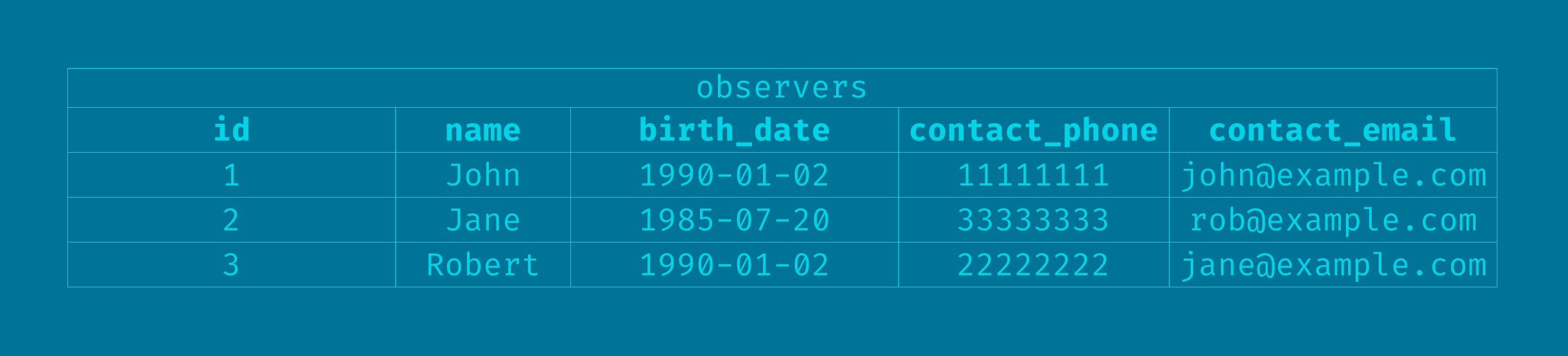
contact information added in the same observer table
But we could also store this information in a contacts table, and add a reference to our already existing observers table. Such contacts table could be:

contact information in its own table
If implemented this way, we need to enforce that no two records exist with the same observer_id value (adding the unique modifier when creating the database, for example).
In this case we can say that:
- an observer has one contact information
- and a contact information has one observer
One to Many
When each record from a table is related to multiple records of another, but records from the latter can only be related to one record of the first. In this case, we add a foreign key (a reference to the primary key of the other table) to specify to which record of the referenced table we are linking this one.
To keep expanding our example, let's say that we have car brands. Each car brand can have multiple cars, and each car belongs only to a car brand. Such implementation, in terms of database tables would look something like this:
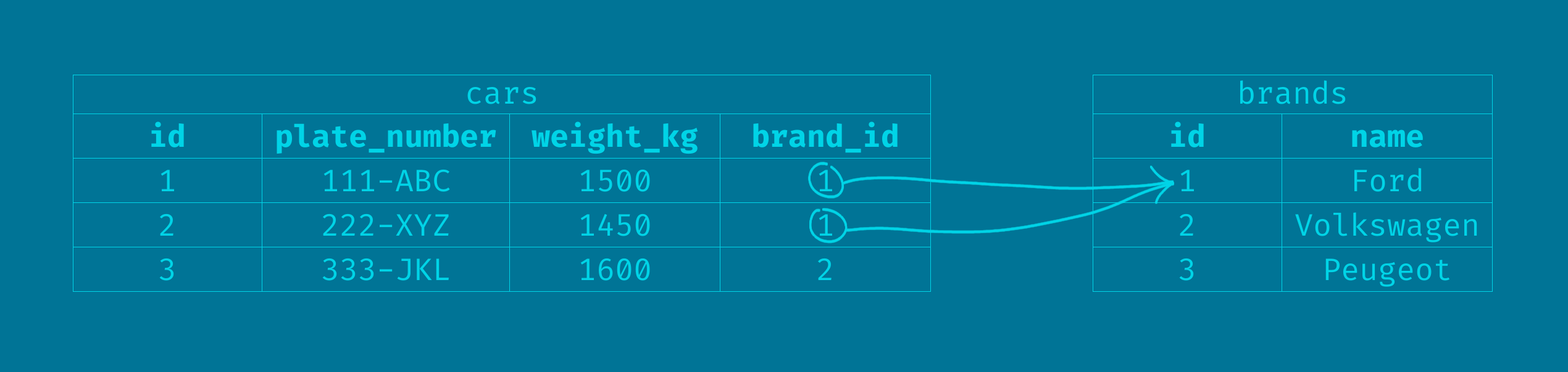
brands and cars tables
Each car is linked to a car brand. And note that multiple cars can have the same "brand_id" value; they belong to the same brand. We can say that:
- a car brand has many cars
- a car belongs to a car brand
Many to Many
When each record from a table can be related to many records of another, and viceversa. In this case, we need to rely on an extra table, called "associate table" (or "linking table", or "pivot table"), that holds the information of which entities are related to which. It'll become more clear with an example.
Let's say we keep track of what features exist in each car. Each car may have many features and each feature may be present in many cars. So, we would probably do something like this:
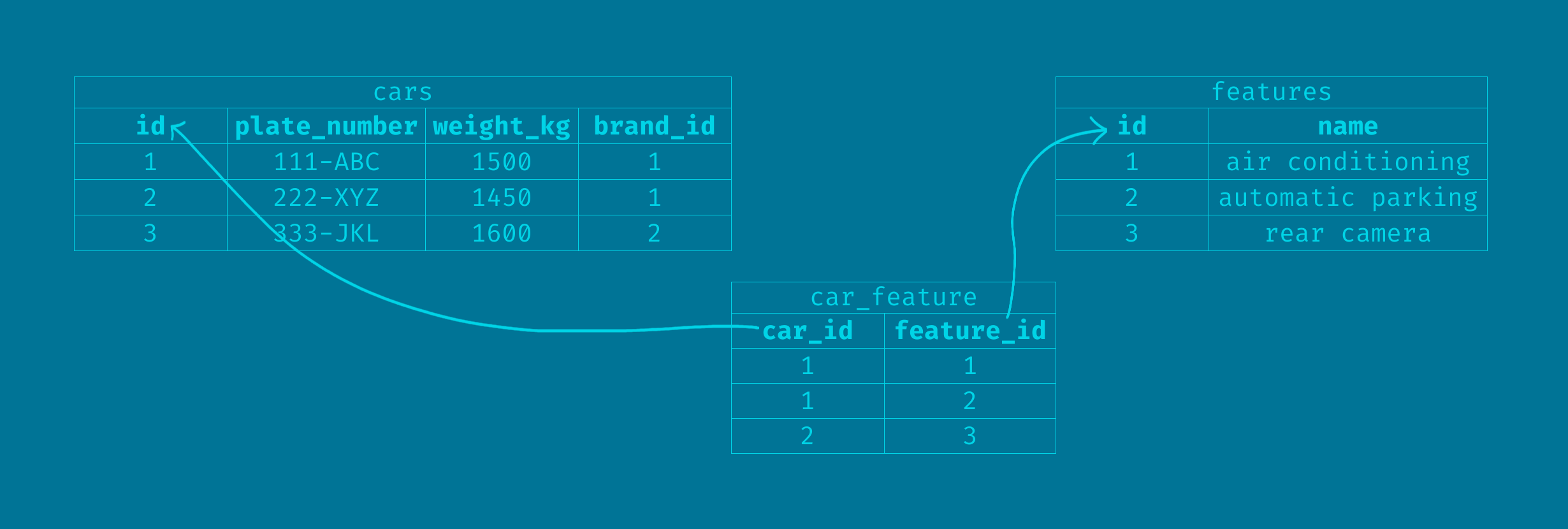
If a record exists in this "pivot table" with the feature_id for a car_id, then it means that the car being referenced has the feature being referenced. In this example, the car with id 1 has the features with id 1 and 2, and the car with id 2 has the feature with id 3
In this relationship, we can say that:
- a car has many features
- a feature is present in many cars
Relational database representations
How does this all translate to the philosophic question of whether quality is objective or subjective?
We said that an objective property is intrinsic to the entity, and it doesn't depend on the appreciation of the observer. If we agree, for example, that the weight of a car can be measured and that that value is the absolute truth, then the "weight" property must live in the "cars" table, like we put it in the examples.
Objective quality
If "quality" were to be an objective property, we would just add the "quality" column to the "cars" table. Like so:

objective quality implementation
As we can see in the diagram, there is no linkage between observers and quality. It is independent of their observations, or even their existence. The cars would keep having the same quality even if no observers existed.
Subjective quality
But, if "quality" were to be a subjective property, then we should have a way to store a different value of quality for each of the observers. Then, each car would have many values of quality (one for each observer), and each observer would have a value of quality for each car evaluated. This would then look like a "many to many" relationship.
Let's name the pivot table "observations". It would look like this:
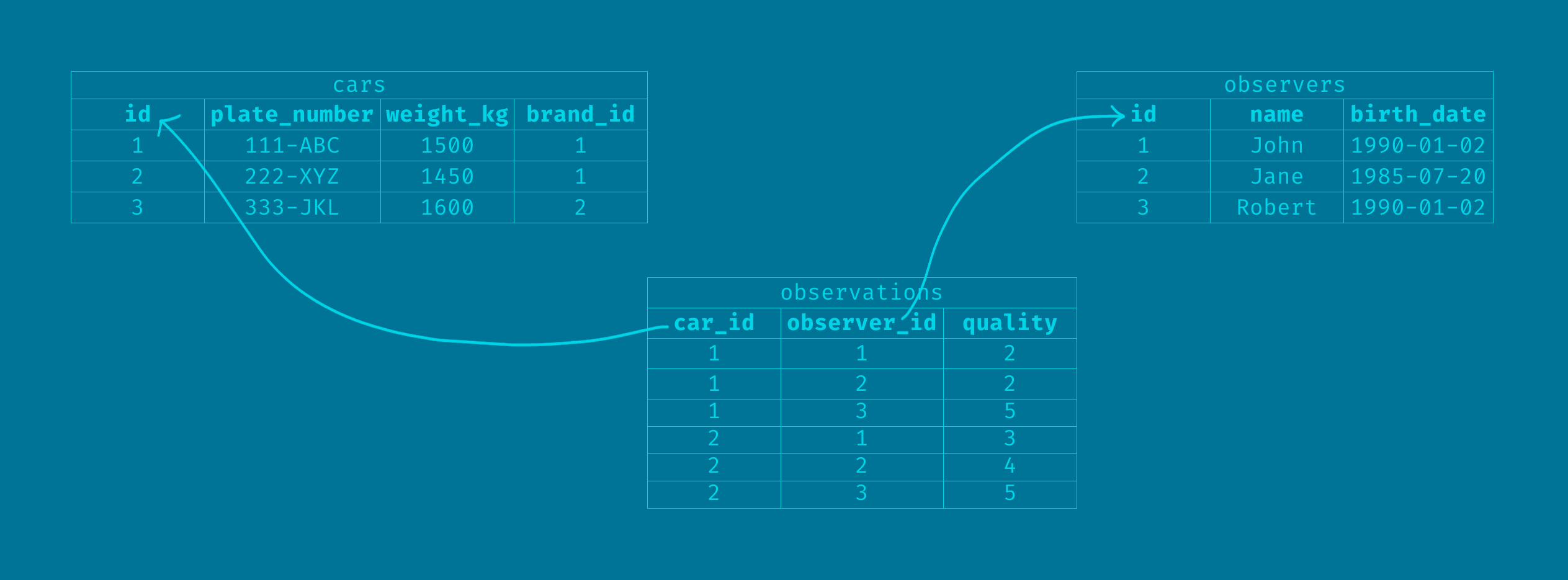
subjective quality implementation
If we asked the 3 observers to evaluate the quality of cars 1 and 2, maybe we get something like the values in the diagram, where the "observer 1" said that the "car 2" has a quality of 3, but the "observer 2" assigned a quality of 4 to the same car.
Here, the value of quality arises from the experimentation of the car by the observer. It is not something intrinsic of the car itself, but it is born from this interaction with the observer and defined by its appreciation. This means that without observers, no quality can be defined for a car.
Closing thoughts
It is really amazing to me how such apparently different topics can be related and used as mental models to try to better understand each other. Are you a software developer? What other software related concepts have you used in other areas? Let me know in the comments!